MLOps project - part 2a: Machine Learning Workflow Orchestration using Prefect
Machine learning workflow orchestration using Prefect.



In the previous blog post, we learned how to use MLflow to train a model and track experiments. In the second post of this series, we will convert the code from the previous phase into a machine learning pipeline. I'll demonstrate how to complete the task using two popular tools: Prefect and ZenML. There are several incredible tools that we cannot include in this article, such as Flyte, Kale, Aro, etc.
We begin with Prefect in this post and ZenML in the next one.
But why do our machine learning services need a pipeline? The ZenML manual describes it in detail [source]:
As an ML practitioner, you are probably familiar with building ML models using Scikit-learn, PyTorch, TensorFlow, or similar. An ML Pipeline is simply an extension, including other steps you would typically do before or after building a model, like data acquisition, preprocessing, model deployment, or monitoring. The ML pipeline essentially defines a step-by-step procedure of your work as an ML practitioner. Defining ML pipelines explicitly in code is great because:
- We can easily rerun all of our work, not just the model, eliminating bugs and making our models easier to reproduce.
- Data and models can be versioned and tracked, so we can see at a glance which dataset a model was trained on and how it compares to other models.
- If the entire pipeline is coded up, we can automate many operational tasks, like retraining and redeploying models when the underlying problem or data changes or rolling out new and improved models with CI/CD workflows.
We may have extensive preprocessing that we do not want to repeat every time we train a model, such as in the last blog post where we generated the corpus list.
We may also need to compare the performance of different models, or wish to deploy the model and monitor data and model performance. Here, ML pipelines come into play, allowing us to specify our workflows as a series of modular processes that can subsequently be combined.
Additionally, we may have a machine learning pipeline that we would like to execute every week. We can put it on a timetable, and if the machine learning model fails or the incoming data fails, we can analyze and resolve the issues.
Let's consider a standard machine learning pipeline:
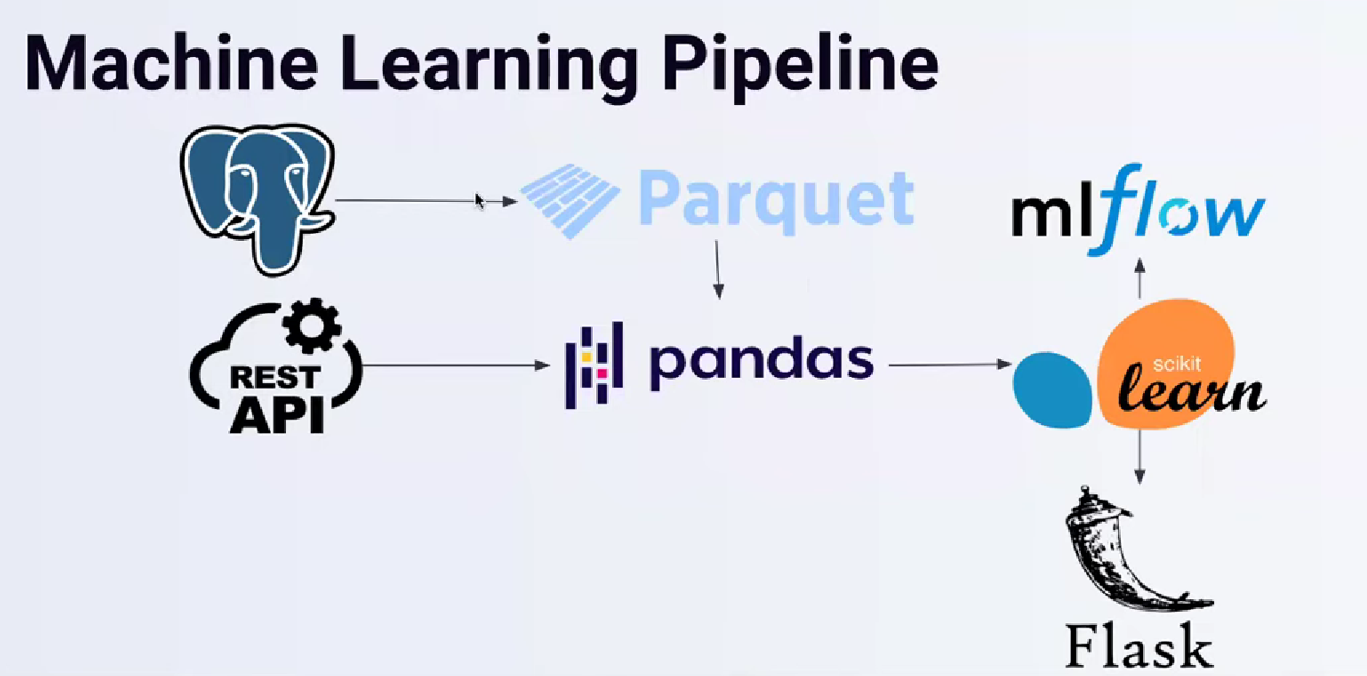
Initially, we have a postgresql database and possibly a process that writes data to a parquet file. Next, we use pandas to consume the parquet file and merge it with the API data we're pulling. After training the model, we register the artifact and conduct experiments with MLflow; if specific conditions are met, we may deploy the model using Flask, for example. Clearly, these phases are interconnected; if one fails, the entire pipeline will be impacted. Failure can occur in even unforeseen ways. For example, inbound data is flawed, the API fails to connect at random, and the same is true for MLflow. Problems may arise if you are using a database to store MLflow artifacts, such as experiments. Workflow orchestration is intended to mitigate the impact of these problems and assist in their resolution.
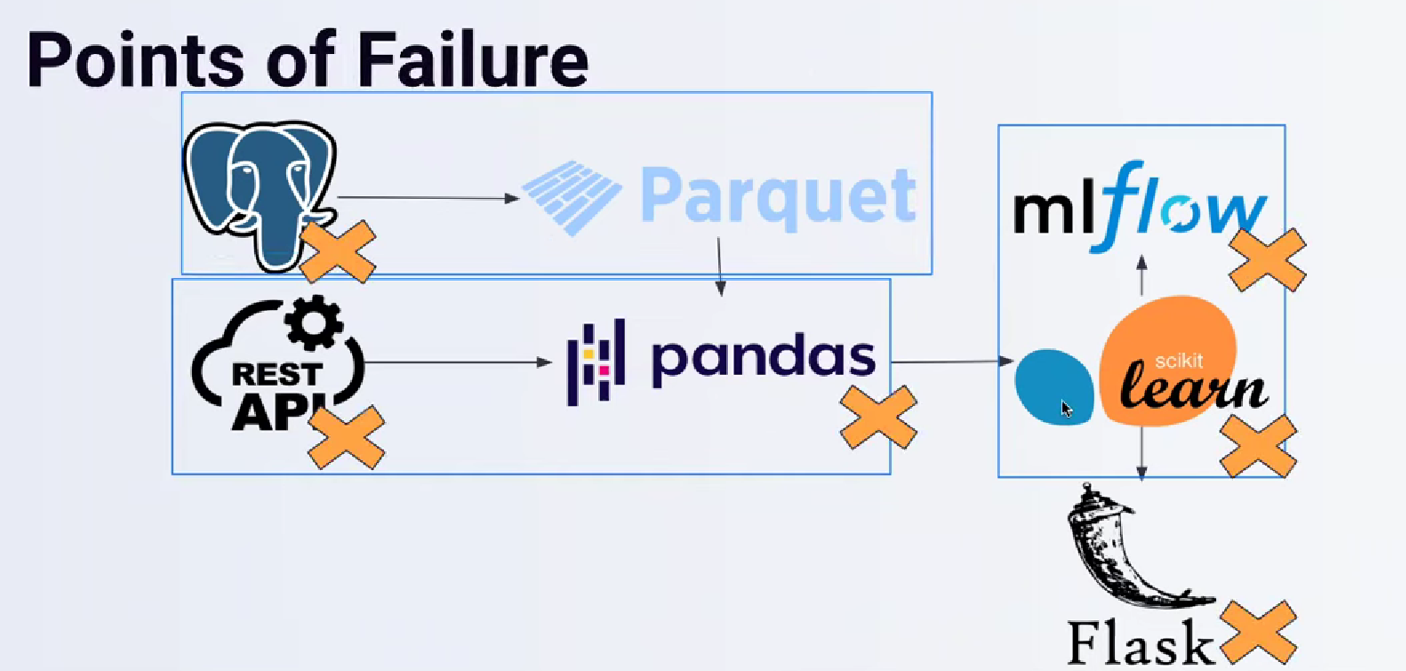
All of these will aid the organization and its developers in completing their tasks and locating issues more quickly, allowing them to devote their attention to something more vital.
Great! let's see how we can do it in practice. Our pipeline would be something like the following:
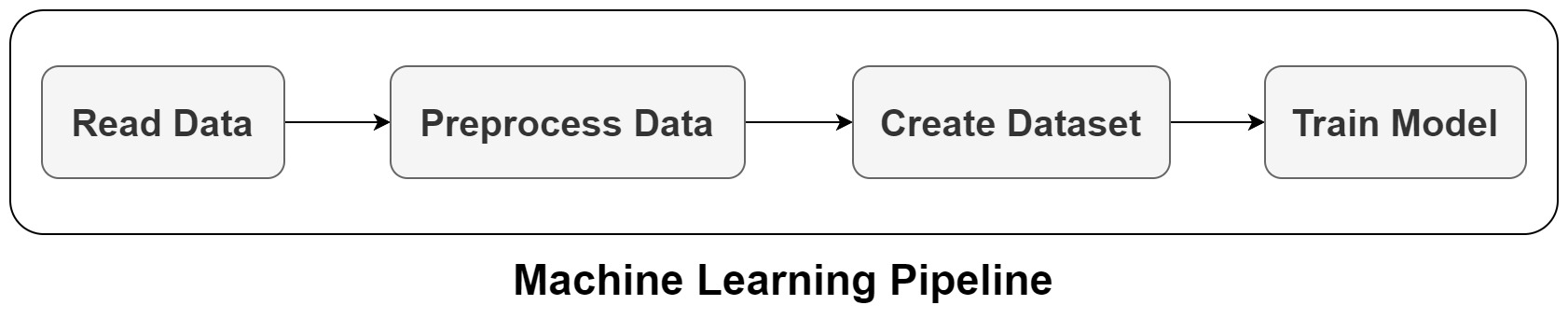
For this project, we don't really need the pipeline, but I just want to show how we can create one. Based on the use case, it may be useful to have a pipeline. For example, if you have a data pipeline that you want to execute periodically or want to have a pipeline to train your machine learning model. Here I just want to show how you can do it if you need it in a project.
Let's see how Prefect can help us.
Prefect
Prefect is a too for the modern data stack to help you monitor, coordinate, and orchestrate dataflows between and across your applications. You can build pipelines, deploy them anywhere, and configure them remotely. If you move data, you probably need the following functionality [source]:
- schedules
- retries
- logging
- caching
- notifications
- observability
Implementing all of these features for your dataflows is a lot of work and takes a lot of time — time that could be better used for functional code.
Prefect 2.0 offers all this functionality and more!
You can easily install Prefect using:
pip install prefectI install Prefect 2.0.4. I see that the API is changing so quickly and you need to use the same version if you want to follow along.
Prefect has some concepts that we try to introduce. You can check the documentation for more details. Here is a small intro for some of them from Prefect documentation:
-
flow: Flows are like functions. They can take inputs, perform work, and return an output. In fact, you can turn any function into a Prefect flow by adding the
@flowdecorator. When a function becomes a flow, its behavior changes, giving it the following advantages:- State transitions are reported to the API, allowing observation of flow execution.
- Input arguments types can be validated.
- Retries can be performed on failure.
- Timeouts can be enforced to prevent unintentional, long-running workflows.
-
task: Tasks are functions: they can take inputs, perform work, and return an output. A Prefect task can do almost anything a Python function can do. Use the
@taskdecorator to designate a function as a task. Calling the task from within a flow function creates a new task run -
Infrastructure: Users may specify an infrastructure block when creating a deployment. This block will be used to specify infrastructure for flow runs created by the deployment at runtime. Infrastructure can only be used with a deployment. When you run a flow directly by calling the flow yourself, you are responsible for the environment in which the flow executes. Infrastructure is attached to a deployment and is propagated to flow runs created for that deployment. Infrastructure is deserialized by the agent and it has two jobs:
- Create execution environment infrastructure for the flow run.
-
Run a Python command to start the prefect.engine in the infrastructure, which retrieves the flow from storage and executes the flow.
-
Infrastructure is specific to the environments in which flows will run. Prefect currently provides the following infrastructure types:
- Process runs flows in a local subprocess.
- DockerContainer runs flows in a Docker container.
- KubernetesJob runs flows in a Kubernetes Job.
-
task runner: Task runners enable you to engage specific executors for Prefect tasks, such as for concurrent, parallel, or distributed execution of tasks. Task runners are not required for task execution. If you call a task function directly, the task executes as a regular Python function, without a task runner, and produces whatever result is returned by the function.
-
Prefect currently provides the following built-in task runners:
- SequentialTaskRunner can run tasks sequentially.
- ConcurrentTaskRunner can run tasks concurrently, allowing tasks to switch when blocking on IO. Tasks will be submitted to a thread pool maintained by anyio.
-
In addition, the following Prefect-developed task runners for parallel or distributed task execution may be installed as Prefect Collections.
- DaskTaskRunner can run tasks requiring parallel execution using dask.distributed.
- RayTaskRunner can run tasks requiring parallel execution using Ray.
-
In our case, I don't want to use these features and just want to run tasks sequentially, which is the default setting.
-
-
Deployments: A deployment is a server-side concept that encapsulates a flow, allowing it to be scheduled and triggered via API. The deployment stores metadata about where your flow's code is stored and how your flow should be run.
-
All Prefect flow runs are tracked by the API. The API does not require prior registration of flows. With Prefect, you can call a flow locally or in a remote environment, which will be tracked.
-
Creating a deployment for a Prefect workflow means packaging workflow code, settings, and infrastructure configuration so that the workflow can be managed via the Prefect API and run remotely by a Prefect agent.
-
When creating a deployment, a user must answer two basic questions:
- What instructions does the agent need to set up an execution environment for my workflow? For example, a workflow may have Python requirements, unique Kubernetes settings, or Docker networking configuration.
- Where and how can the agent access the flow code?
-
A deployment additionally enables you to:
- Schedule flow runs
- Assign tags for filtering flow runs on work queues and in the Prefect UI
- Assign custom parameter values for flow runs based on the deployment
- Create ad-hoc flow runs from the API or Prefect UI
- Upload flow files to a defined storage location for retrieval at run time
- Deployments can package your flow code and pass the manifest to the API — either Prefect Cloud or a local Prefect Orion server run with prefect orion start.
- Here, I just run Prefect locally and do not do any deployment on Docker or Kubernetes or Cloud. I will discuss the possible options to run Prefect on Cloud later.
-
-
Storage: Storage lets you configure how flow code for deployments is persisted and retrieved by Prefect agents. Anytime you build a deployment, a storage block is used to upload the entire directory containing your workflow code (along with supporting files) to its configured location. This helps ensure portability of your relative imports, configuration files, and more.
-
Current options for deployment storage blocks include:
- Local File System Store data in a run's local file system.
- Remote File System Store data in a any filesystem supported by fsspec.
- AWS S3 Storage Store data in an AWS S3 bucket.
- Google Cloud Storage Store data in a Google Cloud Platform (GCP) Cloud Storage bucket.
-
-
Work Queues and Agents: Work queues and agents bridge the Prefect Orion orchestration environment with a user’s execution environment. Work queues define the work to be done, and agents poll a specific work queue for new work.
- You create a work queue on the server. Work queues collect scheduled runs for deployments that match their filter criteria.
- You run an agent in the execution environment. Agents poll a specific work queue for new flow runs, take scheduled flow runs from the server, and deploy them for execution
-
Work queues organize work that agents can pick up to execute. Work queue configuration determines what work will be picked up.
-
Work queues contain scheduled runs from any deployments that match the queue criteria. Criteria is based on deployment tags — all runs for deployments that have the tags defined on the queue will be picked up.
-
These criteria can be modified at any time, and agent processes requesting work for a specific queue will only see matching flow runs.
-
Agent processes are lightweight polling services that get scheduled work from a work queue and deploy the corresponding flow runs.
-
Schedules: Schedules tell the Prefect API how to create new flow runs for you automatically on a specified cadence.
- You can add a schedule to any flow deployment. The Prefect Scheduler service periodically reviews every deployment and creates new flow runs according to the schedule configured for the deployment.
-
Prefect supports several types of schedules that cover a wide range of use cases and offer a large degree of customization:
- Cron is most appropriate for users who are already familiar with cron from previous use.
- Interval is best suited for deployments that need to run at some consistent cadence that isn't related to absolute time.
- RRule is best suited for deployments that rely on calendar logic for simple recurring schedules, irregular intervals, exclusions, or day-of-month adjustments.
We will add Prefect to a Python script containing our code. I will continue with the Keras code from the previous post, although the method is identical for other Scikit-Learn packages. Essentially, we obtain the prior code, including all MLflow-related information, and convert it into functions as our pipeline steps. Converting the python functions to Prefect steps and flow is as easy as wrapping the function using @task and @flow decorators. In our case, the code for training the model might look as follows:
import numpy as np
import pandas as pd
import os
import nltk
import re
if os.path.exists('./corpora'):
os.environ["NLTK_DATA"] = "./corpora"
else:
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
import mlflow
import pickle
from prefect import flow, task
from prefect.task_runners import SequentialTaskRunner
## data loading
@task(
name="read data",
tags=["data"],
retries=3,
retry_delay_seconds=60
)
def read_data(filename='Womens Clothing E-Commerce Reviews.csv'):
data = pd.read_csv(filename,index_col =[0])
print("Data loaded.\n\n")
return data
## preprocess text
@task(
name="preprocess data",
tags=["data"],
retries=3,
retry_delay_seconds=60
)
def preprocess_data(data):
#check if data/corpus is created before or not
if not os.path.exists('data/corpus_y.pickle'):
print("Preprocessed data not found. Creating new data. \n\n")
data = data[~data['Review Text'].isnull()] #Dropping columns which don't have any review
X = data[['Review Text']]
X.index = np.arange(len(X))
y = data['Recommended IND']
corpus =[]
for i in range(len(X)):
review = re.sub('[^a-zA-z]',' ',X['Review Text'][i])
review = review.lower()
review = review.split()
ps = PorterStemmer()
review =[ps.stem(i) for i in review if not i in set(stopwords.words('english'))]
review =' '.join(review)
corpus.append(review)
with open('data/corpus_y.pickle', 'wb') as handle:
pickle.dump((corpus, y), handle)
else:
print("Preprocessed data found. Loading data. \n\n")
with open('data/corpus_y.pickle', 'rb') as handle:
corpus, y = pickle.load(handle)
print("Data preprocessed.\n\n")
return corpus, y
## tokenization and dataset creation
@task(
name="create dataset",
tags=["data"],
retries=3,
retry_delay_seconds=60
)
def create_dataset(corpus, y, test_size=0.2, random_state=0):
tokenizer = Tokenizer(num_words = 3000)
tokenizer.fit_on_texts(corpus)
sequences = tokenizer.texts_to_sequences(corpus)
padded = pad_sequences(sequences, padding='post')
X_train, X_test, y_train, y_test = train_test_split(padded, y, test_size = 0.20, random_state = 0)
print("Dataset created.\n\n")
return X_train, X_test, y_train, y_test, tokenizer
# mlflow.tensorflow.autolog()
@task(
name="tran model",
tags=["model"],
retries=3,
retry_delay_seconds=60
)
def train_model(X_train, y_train, X_test, y_test, tokenizer):
for embedding_dim, batch_size in zip([32, 64, 128], [32, 64, 128]):
with mlflow.start_run():
## model definition
model = tf.keras.Sequential([
tf.keras.layers.Embedding(3000, embedding_dim),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
## training
num_epochs = 50
callback = tf.keras.callbacks.EarlyStopping(
monitor="val_loss",
min_delta=0,
patience=2,
verbose=0,
mode="auto",
baseline=None,
restore_best_weights=False,
)
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
mlflow.set_tag("developer", "Isaac")
mlflow.set_tag("algorithm", "Deep Learning")
mlflow.log_param("train-data", "Womens Clothing E-Commerce Reviews")
mlflow.log_param("embedding-dim", embedding_dim)
print("Fit model on training data")
model.fit(
X_train,
y_train,
batch_size=batch_size,
epochs=num_epochs,
callbacks=callback,
# We pass some validation for
# monitoring validation loss and metrics
# at the end of each epoch
validation_data=(X_test, y_test),
)
## save model and tokenizer
# model.save('models/model_dl.h5')
mlflow.keras.log_model(model, 'models/model_dl')
with open('models/tf_tokenizer.pickle', 'wb') as handle:
pickle.dump(tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)
mlflow.log_artifact(local_path="models/tf_tokenizer.pickle", artifact_path="tokenizer_pickle")
# Evaluate the model on the test data using `evaluate`
print("Evaluate on test data")
results = model.evaluate(X_test, y_test, batch_size=128)
print("test loss, test acc:", results)
mlflow.log_metric("loss", results[0])
mlflow.log_metric("accuracy", results[1])
print("Model training completed.\n\n")
@flow(
name="Sentiment-Analysis-Flow",
description="A flow to run the pipeline for the customer sentiment analysis",
task_runner=SequentialTaskRunner()
)
def main():
tracking_uri = "sqlite:///mlflow.db"
model_name = "customer-sentiment-analysis"
mlflow.set_tracking_uri(tracking_uri)
mlflow.set_experiment(model_name)
data = read_data()
corpus, y = preprocess_data(data)
X_train, X_test, y_train, y_test, tokenizer = create_dataset(corpus, y)
train_model(X_train, y_train, X_test, y_test, tokenizer)
if __name__ == '__main__':
main()
When you trained the mode, you can go to MLflow UI and decide if you want to change the model in the Production stage or not. Then you can easily load the model in the Production stage using a code snippet like this and evaluate it as you wish (maybe creating another pipeline for that):
from mlflow.tracking import MlflowClient
def get_best_model(model_name, client):
model = mlflow.keras.load_model(f"models:/{model_name}/production", dst_path=None)
for mv in client.search_model_versions(f"name='{model_name}'"):
if dict(mv)['current_stage'] == 'Production':
run_id = dict(mv)['run_id']
artifact_folder = "models_pickle" #tokenizer_pickle
client.download_artifacts(run_id=run_id, path=artifact_folder, dst_path='.')
with open(f"{artifact_folder}/tf_tokenizer.pickle", 'rb') as handle:
tokenizer = pickle.load(handle)
print("Model and tokenizer loaded.\n\n")
return model, tokenizer
def test_model(model, X_test, tokenizer):
# Generate predictions (probabilities -- the output of the last layer)
# on new data using `predict`
print("Generate predictions for 3 samples")
predictions = model.predict(X_test[:3])
print("predictions shape:", predictions.shape)
sample_string = "I Will tell my friends for sure"
sample = tokenizer.texts_to_sequences(sample_string)
padded_sample = pad_sequences(sample, padding='post').T
sample_predict = model.predict(padded_sample)
print(f"model prediction for input: {sample_string} \n {sample_predict}")
if __name__ == '__main__':
tracking_uri = "sqlite:///mlflow.db"
model_name = "customer-sentiment-analysis"
client = MlflowClient(tracking_uri=tracking_uri)
model, tokenizer = get_best_model(model_name, client)
test_model(model, X_test, tokenizer)
With wrapping the functions into Prefect, you will get more logs, which helps to observe and debug the pipeline. You can then run the following command to see the Prefect UI dashboard:
prefect orion start
For our code, here is the screenshot:
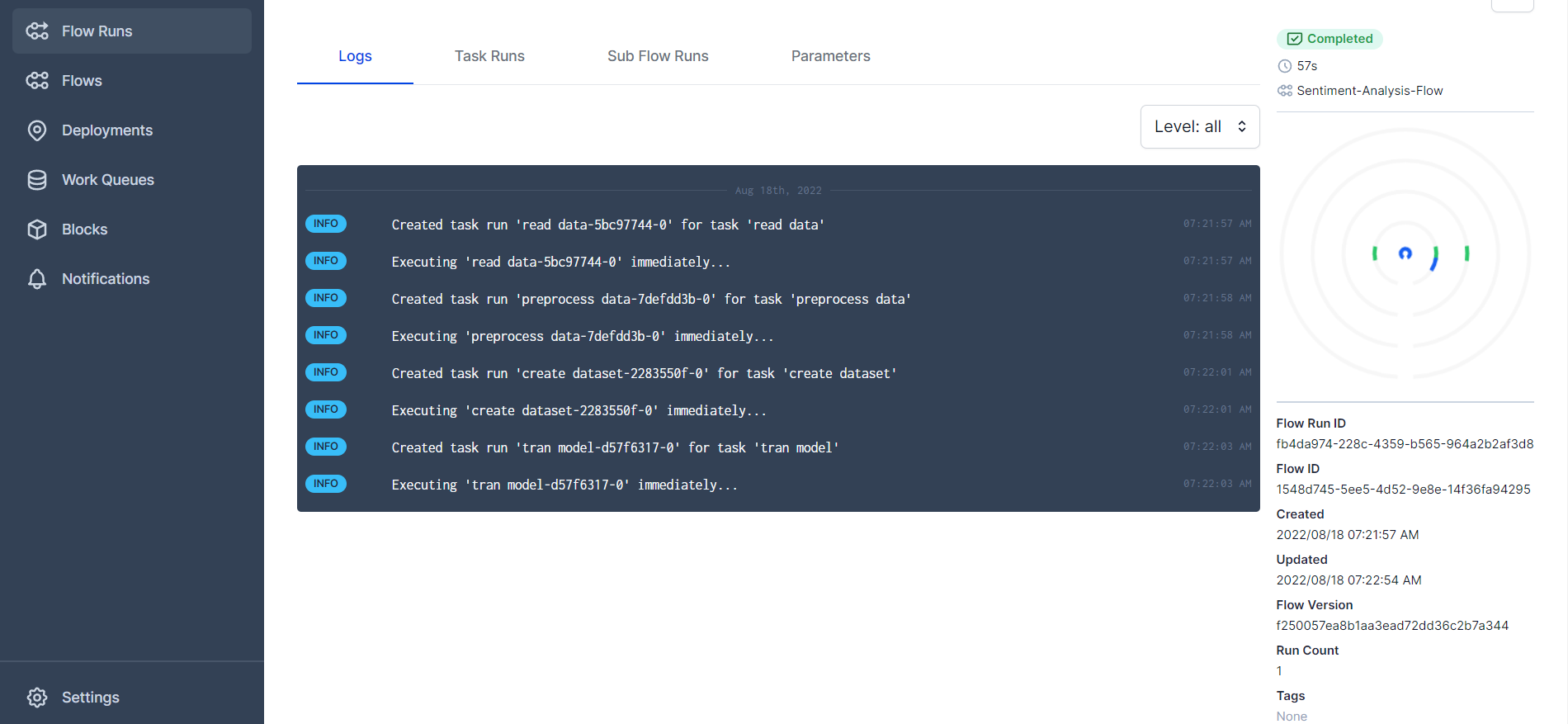
You can see the logs for different tasks and the flow of our code. You can also get much more information from the dashboard. So don't hesitate to play around.
There are a lot of interesting features in Prefect. I really like the concurrency, parallelization, and the async support.
You can check the following videos to learn more about Prefect:
I wrote about another orchestration tool, AirFlow, before. You can find it here. Prefect is a really good alternative for that. It's much simpler and doesn't have all the complexities of using and debugging AirFlow. I highly recommend it for data workflows and ETL.
As I mentioned at the beginning of the post, we don't really need Prefect in this project and I will not deploy it on Cloud. But I discuss how I think it can be used on a Cloud like GCP.
The Prefect community in their slack suggested to use the Prefect Cloud if you really want to use it on Cloud, but I'm not interested in that solution, as I want to have everything on one Cloud like GCP.
One way to use Prefect on Cloud would be easily to have a VM and run Prefect there. Based on the tasks and how much computation they need, you can use more powerfull VMs like a VM with a GPU. In this case, if you want to have a schedule and want to do it using Prefect, I think you have to have the VM and Prefect running all the time, which would be costly if you have a VM with GPU. However, this would be OK for data pipelines and ETL. Check this gist if you are interested in provisioning Prefect server on GCP using Terraform. It is just deploying on a VM again.
For flows that need GPU, one solution might be to have one VM to run Prefect Orion and one VM with GPU for running the flow. You can check this page to start and stop a VM using API. you can containerize your flow and use the VM to run it. You can also use Cloud Run and Cloud Function to run the flow and be triggered by the VM running the server. Note that Cloud Run and Cloud Function have some limitations in time and resources. VM might give you more flexibility.
The other solution would be to have Prefect flows on a VM with any spec you want and use Google Workflows to trigger it. In this case, you will not use Prefect scheduling. You can check here and here to learn more.
You can also interface with BigQuery, Storage, and Secret Manager via prefect-gcp.
The more scalable solution that most big companies with structured data teams do is to run the flow on Docker and Kubernetes.
I also see that in Prefect 1.0, they have a solution to run the flow on VertexAI, which is the Google's serverless and managed service for machine learning. you can run the flow on VertexAI and configure the machine you use. After the flow is finished, the machine will turn off. But this feature is not ready for Prefect 2.0 yet and will be added soon.
Additionally, you may view the following videos to learn how to use Prefect on a VM on AWS:
That's it for this post. We will check ZenML in our next blog post.
Note: I will update this post when I learn more about Prefect deployment on Cloud.