Data Engineering - Week 4
Week 4 - Data Engineering Zoomcamp course: Analytics Engineering



Note: The content of this post is from the course videos, my understandings and searches, and reference documentations.
This week we will learn about Analytics Engineering. In the previous weeks, we ingested the NY taxi data into Google Cloud Storage and created BigQuery tables and performed some queries on them. This week we will learn how to use DBT to do Analytics and Transformation (the T in ELT).
What Is Data Analytics Engineering
Analytics Engineers sit at the intersection of business teams, Data Analytics and Data Engineering and are responsible for bringing robust, efficient, and integrated data models and products to life. Analytics Engineers speak the language of business teams and technical teams, able to translate data insights and analysis needs into models powered by the Enterprise Data Platform. The successful Analytics Engineer is able to blend business acumen with technical expertise and transition between business strategy and data development. [ref]
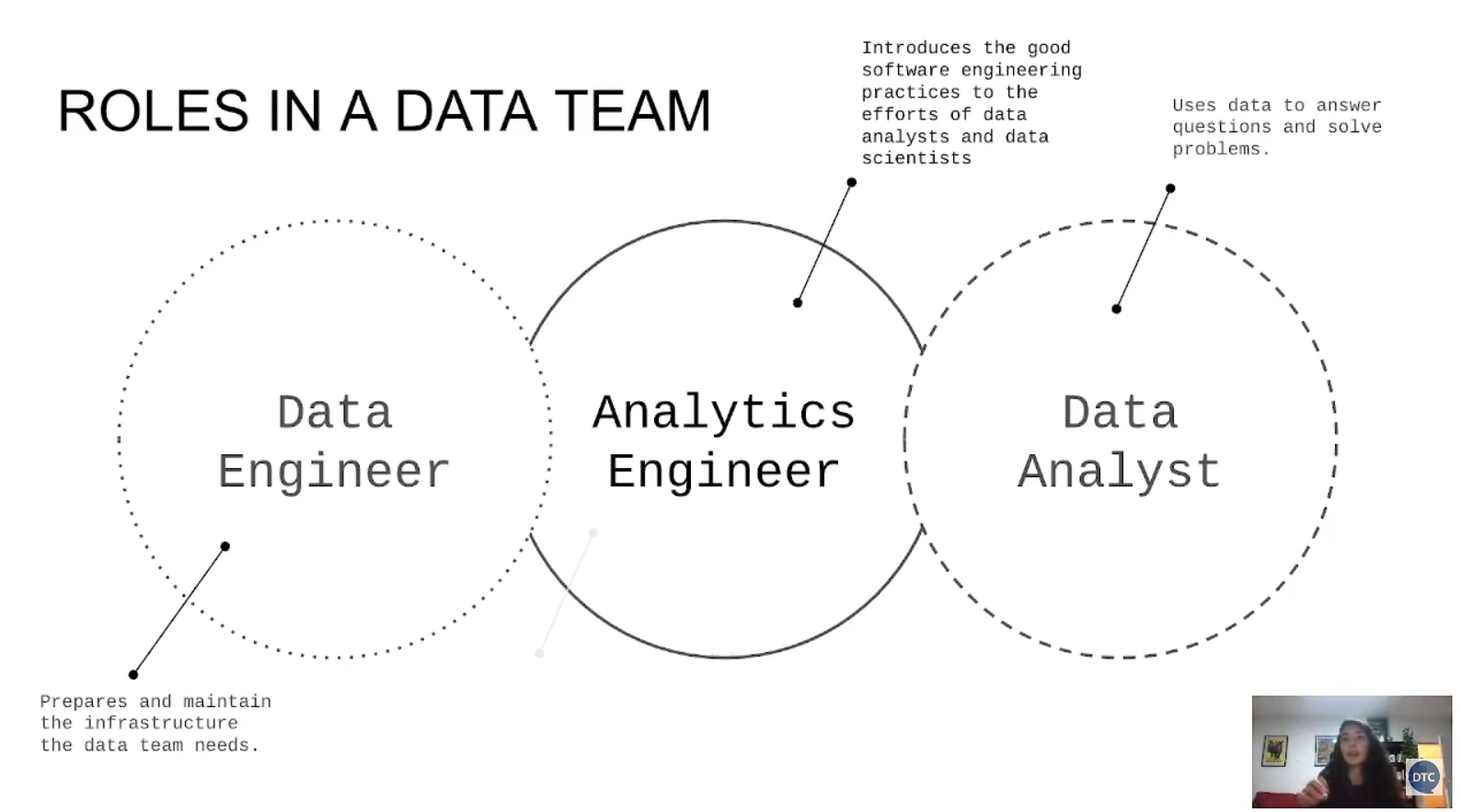
Data Build Tool (DBT)
dbt (data build tool) enables analytics engineers to transform data in their warehouses by simply writing select statements. dbt handles turning these select statements into tables and views.
dbt does the T in ELT (Extract, Load, Transform) processes – it doesn’t extract or load data, but it’s extremely good at transforming data that’s already loaded into your warehouse. [dbt docs]
The following image shows exactly where dbt is in the ELT process:
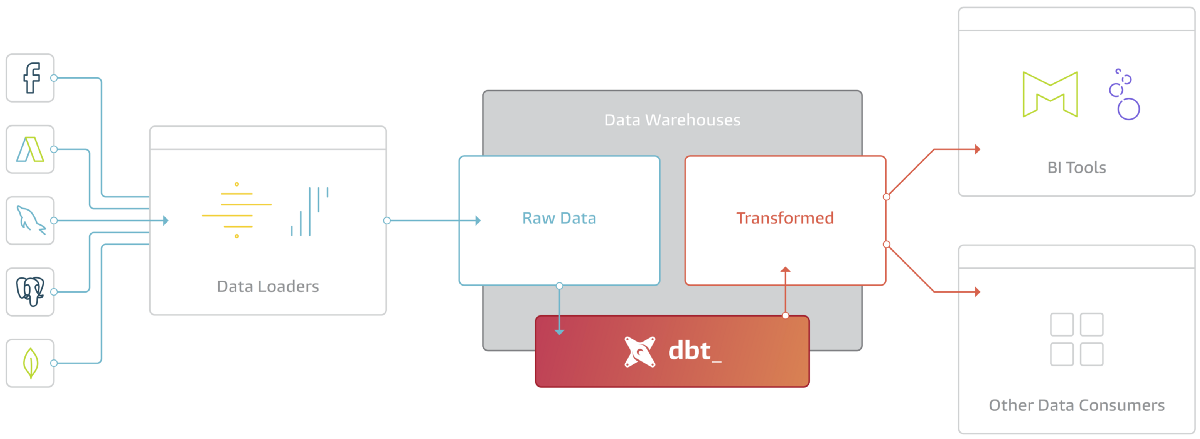
Read this amazing blog post to learn more.
A dbt project is a directory of .sql and .yml files. The directory must contain at a minimum: [dbt docs]
- Models: A model is a single .sql file. Each model contains a single select statement that either transforms raw data into a dataset that is ready for analytics, or, more often, is an intermediate step in such a transformation.
- A project file: a dbt_project.yml file which configures and defines your dbt project. Projects typically contain a number of other resources as well, including tests, snapshots, and seed files.
dbt connects to your data warehouse to run data transformation queries. As such, you’ll need a data warehouse with source data loaded in it to use dbt. dbt natively supports connections to Snowflake, BigQuery, Redshift and Postgres data warehouses, and there’s a number of community-supported adapters for other warehouses. [dbt docs%20enables,statements%20into%20tables%20and%20views.)]
Check also this video to get a better understanding:
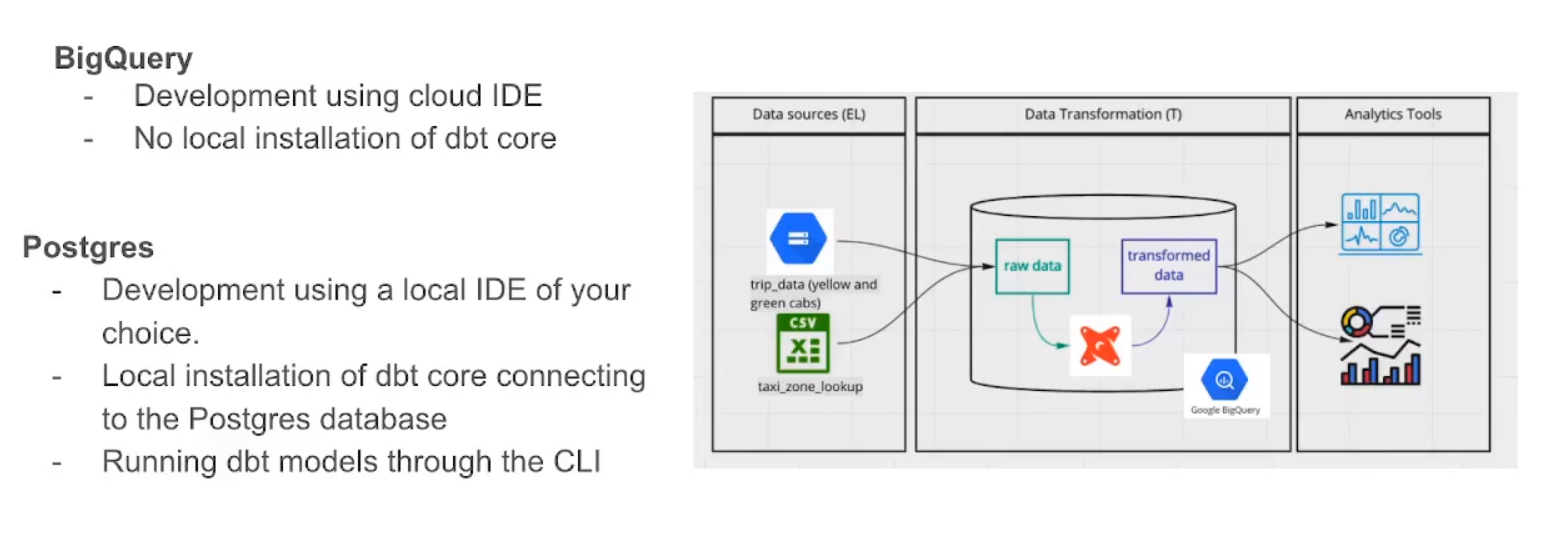
Starting a dbt project
We can start creating a dbt project by using the starter project. As we mentioned before, there is a .yml file for each project as follows:
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models
name: 'my_new_project'
version: '1.0.0'
# This setting configures which "profile" dbt uses for this project.
profile: 'default'
# These configurations specify where dbt should look for different types of files.
# The `source-paths` config, for example, states that models in this project can be
# found in the "models/" directory. You probably won't need to change these!
source-paths: ["models"]
analysis-paths: ["analysis"]
test-paths: ["tests"]
data-paths: ["data"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
target-path: "target" # directory which will store compiled SQL files
clean-targets: # directories to be removed by `dbt clean`
- "target"
- "dbt_modules"
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/ directory
# as tables. These settings can be overridden in the individual model files
# using the `` macro.
models:
my_new_project:
# Applies to all files under models/example/
example:
materialized: view
You can install dbt locally or use it in the cloud. If you want to install it locally and use CLI, follow these instructions.
We will use cloud for this week without install dbt locally. We will use web editor to build our project and execute dbt commands. First you need to create an account here. After creating the account, it will guide you to build your first project. Just follow the steps. In the process, it will ask you to select the datawarehouse you want to connect to. You can follow the official instruction here or the course instructions here to connect your BQ data warehouse to dbt cloud. It will also ask to connect to your GitHub repo (by giving you a ssh-key which you need to add to your github) if you have the project there and want to work on that.
If you do all of these steps and add the course repo (I used my own forked version) and initialize the project, you will see sth like this:
To learn more about creating dbt project on cloud, watch the following video:
And to learn more about creating dbt project locally and use postgres, watch the following video: (you can also work with BigQuery from you local dbt)